Interface class for nearest neighbour imputation (NNI) algorithms. More...
#include <yat/utility/NNI.h>
Public Member Functions | |
| NNI (const utility::Matrix &matrix, const utility::Matrix &weight, const unsigned int neighbours) | |
| virtual unsigned int | estimate (void)=0 |
| Function doing the imputation. More... | |
| const utility::Matrix & | imputed_data (void) const |
| const std::vector< size_t > & | not_imputed (void) const |
Protected Member Functions | |
| std::vector< std::pair< size_t, double > > | calculate_distances (const size_t) const |
| std::vector< size_t > | nearest_neighbours (const size_t, const std::vector< std::pair< size_t, double > > &) const |
Protected Attributes | |
| const utility::Matrix & | data_ |
| utility::Matrix | imputed_data_ |
| unsigned int | neighbours_ |
| std::vector< size_t > | not_imputed_ |
| const utility::Matrix & | weight_ |
Detailed Description
Interface class for nearest neighbour imputation (NNI) algorithms.
NNI algorithms implemented here is discussed in documents created in the WeNNI project. This document will be released for public access, and the necessary information for retrieving that document will be provided here.
Short introduction to NNI is that one may want to improve (correct) uncertain data. Here, the data to be imputed is stored in a matrix where rows similar to each other are used to adjust uncertain data. The data matrix is accompanied by a weight (uncertainty) matrix defining what data is to be considered as 'certain' and what data is uncertain. The weight matrix can be binary with 1's indicating that the data does not need corrections, whereas a 0 means that the data should be replaced by an imputed value. Naturally, the weight matrix can also be continuous where values between 0 and 1 defines how certain a data element is.
The imputation depends on how similarity of rows of data is defined and on the number of closest neighbours (here; rows) to use in the imputation can be set.
Implementation issues
The current implementation treats rows where all data are tagged are completely uncertain, i.e. all weights are zero, by ignoring these lines in nearest neighbourhood calculations. Importantly, this type of data are not changed (imputed) either since there is no close neighbourhood defined for this data.
Rows that is completely identical in an imputation algorithm sense will give problems since the distance between will usually become zero. This is solved by setting zero distance to a small number. Identical rows in this context are basically a comparison between elements with non-zero uncertainty weights only, and all these elements are equal. Zero weight elements are not used in the comparison since these are considered as non/sense values.
Constructor & Destructor Documentation
| theplu::yat::utility::NNI::NNI | ( | const utility::Matrix & | matrix, |
| const utility::Matrix & | weight, | ||
| const unsigned int | neighbours | ||
| ) |
Base constructor for the nearest neighbour imputation algorithms.
Member Function Documentation
|
protected |
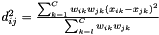 where C is the number of columns
where C is the number of columns
|
pure virtual |
Function doing the imputation.
The return value can be used as an indication of how well the imputation worked. The return value should be zero if proper pre-processing of data is done. An example of bad data is a matrix with a column of zero weights, another is a corresponding situation with a row with all weights zero.
- Returns
- The number of rows that have at least one value not imputed.
Implemented in theplu::yat::utility::WeNNI, and theplu::yat::utility::kNNI.
| const utility::Matrix& theplu::yat::utility::NNI::imputed_data | ( | void | ) | const |
- Returns
- A const reference to the modified data.
|
protected |
Contributing nearest neighbours are added up to the user set number, and neighbours are disqualified if their element (column) weight is zero
| const std::vector<size_t>& theplu::yat::utility::NNI::not_imputed | ( | void | ) | const |
- Returns
- indices of rows in data matrix not imputed
Member Data Documentation
|
protected |
original data matrix
|
protected |
data after imputation
|
protected |
number of neighbor to use
|
protected |
which rows are not imputed due to lack of data
|
protected |
weight matrix
The documentation for this class was generated from the following file:
- yat/utility/NNI.h
